
背景
Dynamicgo 是字节跳动自研的高性能 Golang RPC 编解码基础库,能在动态处理 RPC 数据(不依赖代码生成)的同时保证高性能,主要用于实现高性能 RPC 动态代理场景(见 dynamicgo 介绍)。
Protobuf 是一种跨平台、可扩展的序列化数据传输协议,该协议序列化压缩特性使其具有优秀的传输速率,在常规静态 RPC 微服务场景中已经得到了广泛的应用。但是对于上述特殊的动态代理场景,我们调研发现目前业界主流的 Protobuf 协议基础库并不能满足我们的需求:
- google.golang.org/protobuf:Protobuf 官方源码支持协议转换和字段动态反射。实现过程依赖于反射完整的中间结构体 Message 对象来进行管理,使用过程中带来了很多不必要字段的数据性能开销,并且在处理多层嵌套数据时操作较为复杂,不支持内存字符串 io 流 IDL 解析。
- github.com/jhump/protoreflect:Protobuf 动态反射第三方库可支持文件和内存字符串 io 流 IDL 解析,适合频繁泛化调用,协议转换过程与官方源码一致,均未实现 inplace 转换,且内部实现存在Go版本兼容性问题。
- github.com/cloudwego/fastpb:Protobuf 快速序列化第三方库,通过静态代码方式读写消息结构体,不支持协议转换和动态 IDL 解析。
因此如何设计自研一个功能完备、高性能、可扩展的 Protobuf 协议动态代理基础库是十分有必要的。
@khan-yin和@iStitches两位同学经过对 Protobuf 协议源码机制的深入学习,设计了高性能 Protobuf 协议动态泛化调用链路,能满足绝大多数 Protobuf 动态代理场景,并且性能优于官方实现,目前 PR#37 已经合入代码仓库。Protobuf 设计思想
由于 Protobuf 协议编码格式细节较为复杂,在介绍链路设计之前我们有必要先了解一下 Protobuf 协议的设计思想,后续的各项设计都将在严格遵守该协议规范的基础上进行改进。
官方源码链路思想
Protobuf 源码链路过程主要涉及三类数据类型之间的转换,以 Message 对象进行管理,自定义 Value 类实现反射和底层存储,用 Message 对象能有效地进行管理和迁移,但也带来了许多反射和序列化开销。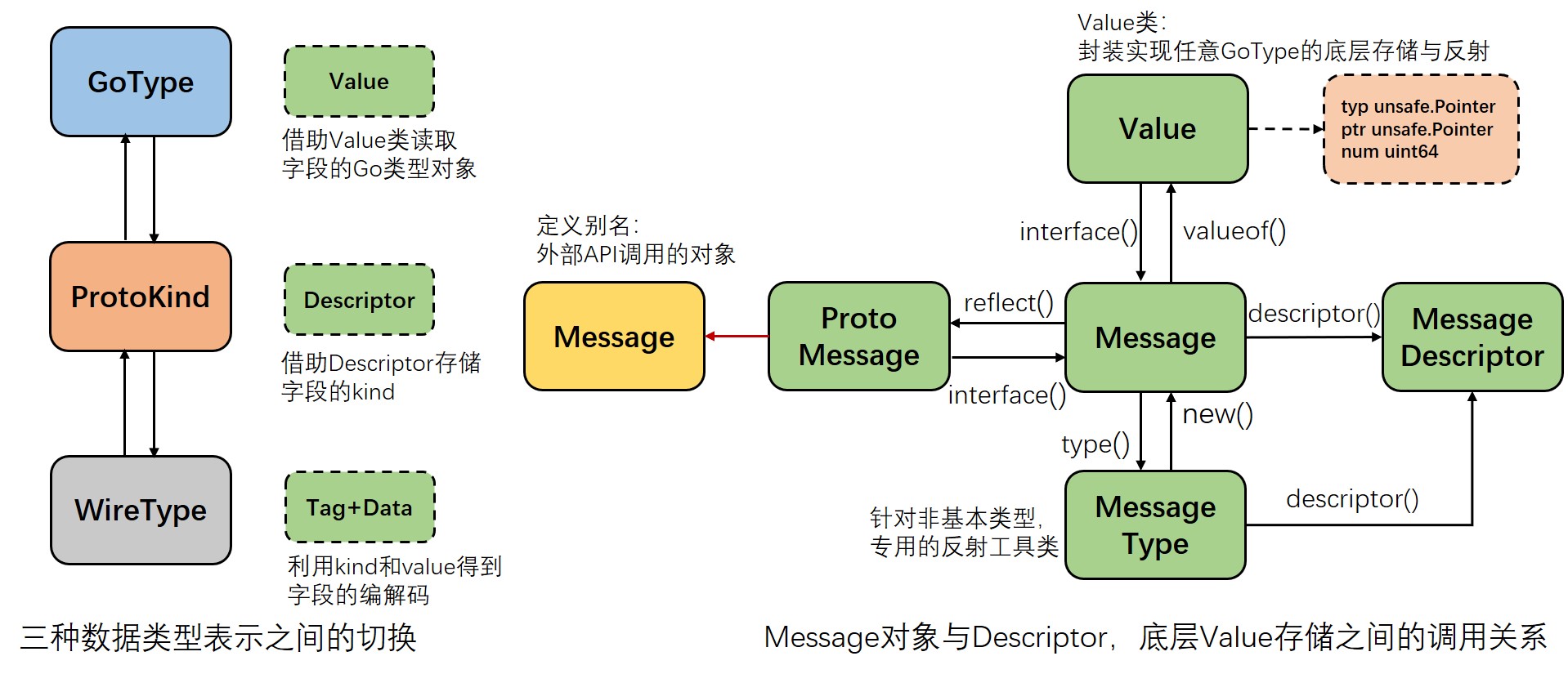
Protobuf编码格式
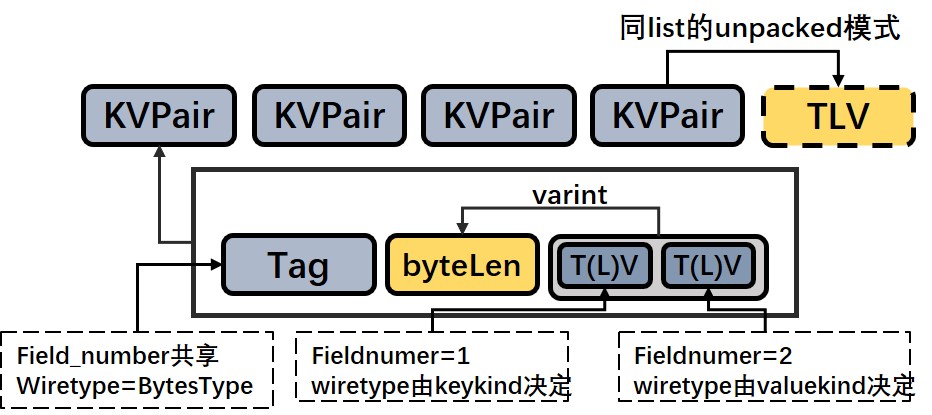
Protobuf 编码字段格式大体上遵循 TLV(Tag,Length,Value) 的结构,但针对具体的类型存在一些编码差异,这里我们将较为全面的给出常见类型的编码模式。
Message Field
Protobuf 的接口必定包裹在一个 Message 类型下,因此无论是 request 还是 response 最终都会包裹成一个 Message 对象,那么 Field 则是 Message 的一个基本单元,任何类型的字段都遵循这样的 TLV 结构: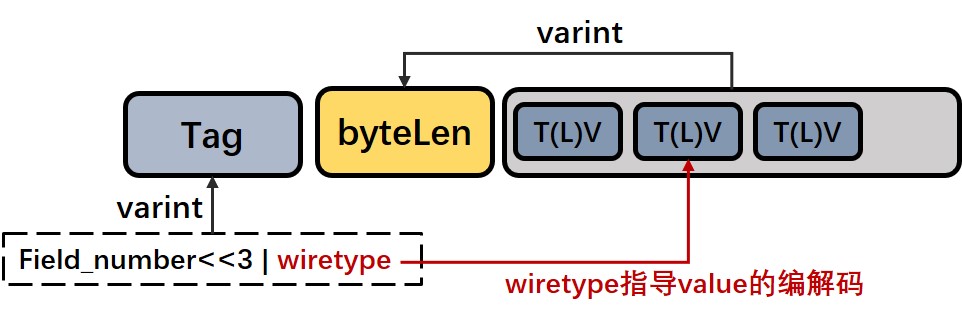
- Tag 由字段编号 Field_number 和 wiretype 两部分决定,对位运算后的结果进行 varint 压缩,得到压缩后的字节数组作为字段的 Tag。
- wiretype 的值则表示的是 value 部分的编码方式,可以帮助我们清楚如何对 value 的读取和写入。到目前为止,wiretype只有 VarintType,Fixed32Type,Fixed64Type,BytesType 四类编码方式。其中VarintType 类型会被压缩后再编码,属于 Fixed32Type 和 Fixed64Typ 固定长度类型则分别占用4字节和8字节,而属于不定长编码类型 BytesType 的则会编码计算 value 部分的 ByteLen 再拼接 value 。
- ByteLen 用于编码表示 value 部分所占的字节长度,同样我们的 bytelen 的值也是经过 varint 压缩后得到的,但bytelen并不是每个字段都会带有,只有不定长编码类型 BytesType 才会编码 bytelen 。ByteLen 由于其不定长特性,计算过程在序列化过程中是需要先预先分配空间,记录位置,等写完内部字段以后再回过头来填充。
- Value 部分是根据 wiretype 进行对应的编码,字段的 value 可能存在嵌套的 T(L)V 结构,如字段是 Message,Map等情况。
Message
关于 Message 本身的编码是与上面提到的字段编码一致的,也就是说遇到一个 Message 字段时,我们会先编码 Message 字段本身的 Tag 和 bytelen,然后再来逐个编码 Message 里面的每个字段。但需要提醒注意的是,在最外层不存在包裹整个 Message 的 Tag 和 bytelen 前缀,只有每个字段的 TLV 拼接。
List
list字段比较特殊,为了节省存储空间,根据list元素的类型分别采用不同的编码模式。
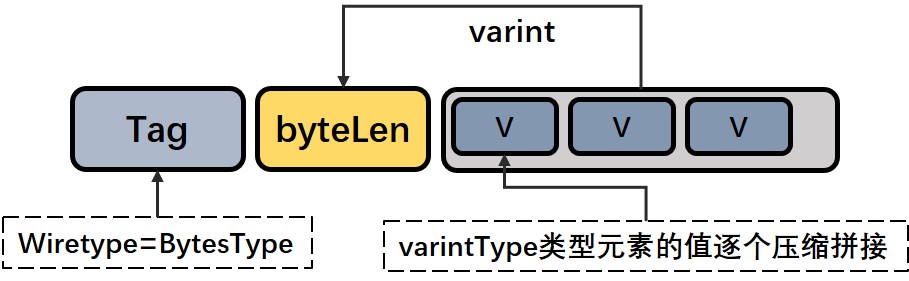
- Packed List Mode
如果list的元素本身属于 VarintType/Fixed32Type/Fixed64Type 编码格式,那么将采用 packed 模式编码整个 List ,在这种模式下的 list 是有 bytelen 的。Protobuf3 默认对这些类型启用 packed。
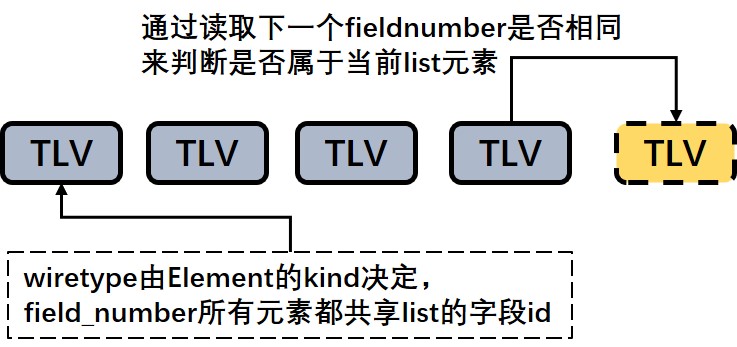
- UnPacked List Mode
当 list 元素属于 BytesType 编码格式时,list 将使用 unpacked 模式,直接编码每一个元素的 TLV,这里的 V 可能是嵌套的如List模式,那么 unpacked 模式下所有元素的 tag 都是相同的,list 字段的结束标志为与下一个 TLV 字段编码不同或者到达 buf 末尾。
Map
Map 编码模式与 unpacked list 相同,根据官方设计思想,Map 的每个 KV 键值对其实本质上就是一个 Message,固定 key 的 Field_number 是1,value 的 Field_number 是2,那么 Map 的编码模式就和 List<Message> 一致了。
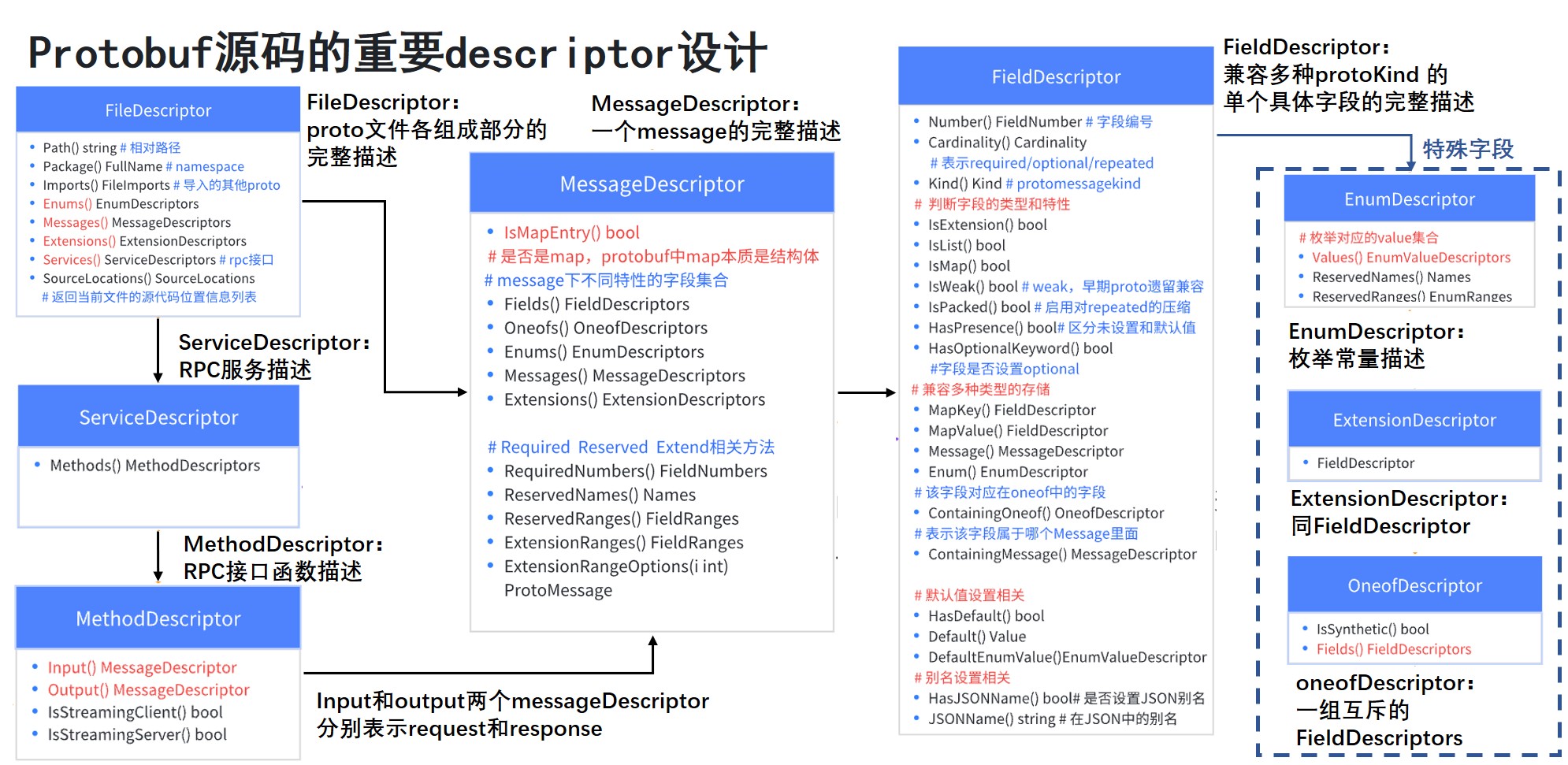
源码 Descriptor 细节
这里主要介绍一下源码的 descriptor 设计上的一些需要注意的细节。
- Service 接口由 ServiceDescriptor 来描述,ServiceDescriptor 当中可以拿到每个 rpc 函数的 MethodDescriptor。
- MethodDescriptor 中 Input() 和 output() 两个函数返回值均为 MessageDescriptor 分别表示 request 和 response 。
- MessageDescriptor 专门用来描述一个 Message 对象(也可能是一个 MapEntry ),可以通过 Fields() 找到每个字段的 FieldDescriptor 。
- FieldDescriptor 则兼容所有类型的描述。
动态反射
针对 Protobuf 的反射使用场景,我们归纳出以下需求:
- 具有完整的结构自描述和具体类型反射功能,兼容 scalar 类型以及复杂嵌套的 MESSAGE/LIST/MAP 结构。
- 支持字节流模式下的对任意局部进行动态数据修改与遍历。
- 保证数据可并发读。
这里我们借助 Go reflect 的设计思想,把通过 IDL 解析得到的准静态类型描述(只需跟随 IDL 更新一次)TypeDescriptor 和 原始数据单元 Node 打包成一个完全自描述的结构—— Value,提供一套完整的反射 API。
IDL 静态文件 parse 过程:
为了提供文件流和内存字符串 io 流的 idl 文件解析,同时保证保证 go 版本兼容性,我们利用protoreflect@v1.8.2解析结果完成按需构造。从实现原理上来看,与高版本 protoreflect 利用protocompile对原始链路再 make 出源码的 warp 版本一致,更好的实现或许是处理利用 protoreflect 中的 ast 语法树构造。
Descriptor设计
Descriptor 的设计原理基本尽可能与源码保持一致,但为了更好的自反射性,我们抽象了一个 TypeDescriptor 来表示更细粒度的类型。
FieldDescriptor
|
FieldDescriptor: 设计上希望变量和函数作用与源码 FieldDescriptor 基本一致,增加*TypeDescriptor可以更细粒度的反应类型以及对 FieldDescriptor 的 API 实现。kind:与源码 kind 功能一致,LIST 情况下 kind 是列表元素的 kind 类型,MAP 和 MESSAGE 情况下都为 messagekind。
TypeDescriptor
|
baseId:因为对于 LIST/MAP 类型的编码特殊性,如在 unpack 模式下,每一个元素都需要编写 Tag,我们必须在构造时针对 LIST/MAP 提供 fieldnumber,来保证读取和写入的自反射性。msg:这里的 msg 不是仅 Message 类型独有,主要是方便 J2P 部分对于 List 和裁剪场景中 map 获取可能存在 value 内部字段缺失的 MapEntry 的 MassageDescriptor(在源码的设计理念当中 MAP 的元素被认为是一个含有 key 和 value 两个字段的 message )的时候能直接利用 TypeDescriptor 进入下一层嵌套。typ:这里的 Type 是对源码的 FieldDescriptor 更细粒度的表示,即对 LIST/MAP 做了单独定义
MessageDescriptor
|
MessageDescriptor: 利用 Tire 树结构实现更高性能的字段 id 和字段 name 的存储和查找。
数据存储设计
从协议本身的 TLV 嵌套思想出发,我们利用字节流的编码格式,建立健壮的自反射性结构体处理任意类型的解析。
Node结构
|
具体的存储规则如下:
- 基本类型 Node 表示:指针 v 的起始位置不包含 tag,指向 (L)V,t = 具体类型。
- MESSAGE 类型:指针 v 的起始位置不包含 tag,指向 (L)V,如果是 root 节点,那么 v 的起始位置本身没有前缀的 L,直接指向了 V 即第一个字段的 tag 上,而其余子结构体都包含前缀 L。
- LIST类型:为了兼容 List 的两种模式和自反射的完整性,我们必须包含 list 的完整片段和 tag。因此 List 类型的节点,v 指向 list 的 tag 上,即如果是 packed 模式就是 list 的 tag 上,如果是 unpacked 则在第一个元素的 tag 上。
- MAP类型:Map 的指针 v 也指向了第一个 pair 的 tag 位置。
- UNKNOWN类型Node表示:无法解析的合理字段,Node 会将 TLV 完整存储,多个相同字段 Id 的会存到同一节点,缺点是内部的子节点无法构建,同官方源码unknownFields原理一致。
- ERROR类型Node表示:在 setnotfound 中,若片段设计与上述规则一致则可正确构造插入节点。
虽然 MAP/LIST 的父级 Node 存储有些变化,但是其子元素节点都是基本类型 / MESSAGE,所以叶子节点存储格式都是基本的 (L)V,这也便于序列化和数据基本单位的原子操作。
Value结构
value 的结构本身是对 Node 的封装,将 Node 与相应的 descriptor 封装起来,但不同于 thrift,在 Protobuf 当中由于片段无法完全自解析出具体类型,之后的涉及到具体编码的部分操作不能脱离 descriptor,部分 API 实现只能 Value 类作为调用单位。
|
由于从 rpc 接口解析后我们直接得到了对应的 TypeDescriptor,再加上 root 节点本身没有前缀TL的独特编码结构,我们通过设置IsRoot标记来区分 root 节点和其余节点,实现 Value 结构的 Descriptor 统一。
数据编排
不同于源码 Message 对象数据动态管理的思想,我们设计了更高效的动态管理方式。我们借助 DOM (Document Object Model)思想,将原始字节流数据层层包裹的结构,抽象成多层嵌套的 BTree 结构,实现对数据的定位,切分,裁剪等操作的 inplace 处理。
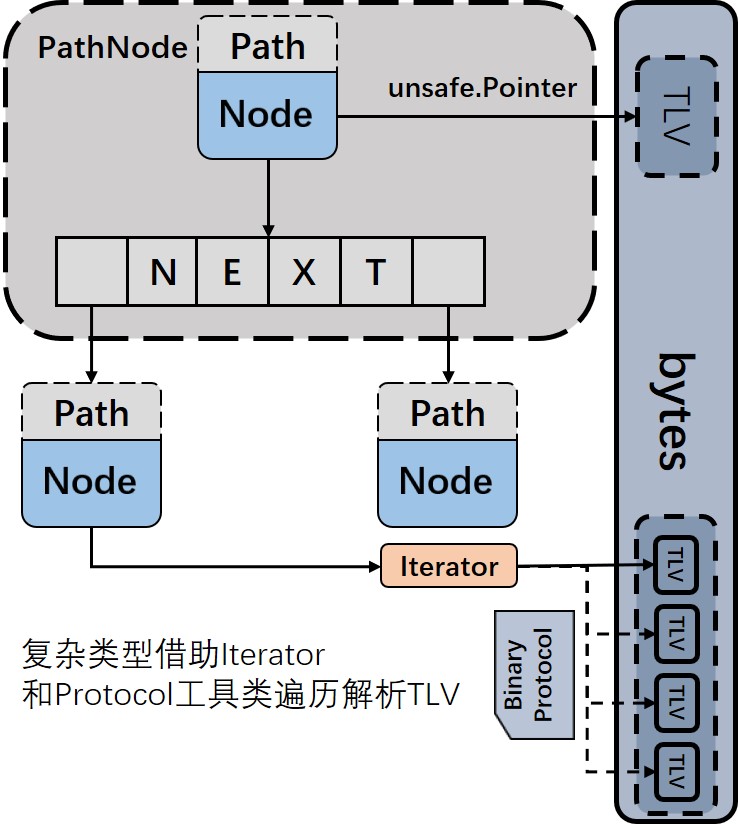
Path与PathNode
为了准确描述 DOM 中数据节点之间的嵌套关系,我们设计了 Path 结构,在 Path 的基础上,我们组合对应的数据单元 Node,然后再通过一个 Next 数组动态存储子节点,便可以组装成一个类似于 BTree 的泛型单元结构。
|
构建DOM Tree
构建 DOM 支持懒加载和全加载,在懒加载模式下 LIST/MAP 的 Node 当中 size 不会同步计算,而全加载在构造叶子节点的同时顺便更新了 size,构造后的节点都将遵循上述存储规则,具有自反射性和结构完整性。
查找字段
支持任意Node查找,查找函数设计了三个外部API:GetByPath,GetByPathWithAddress,GetMany。
GetByPath:返回查找出来的 Value ,查找失败返回 ERROR 类型的节点。GetByPathWithAddress:返回Value和当前调用节点到查找节点过程中每个 Path 嵌套层的 tag 位置的偏移量。[]address与[]Path个数对应,若调用节点为 root 节点,那么可记录到 buf 首地址的偏移量。GetMany:传入当前嵌套层下合理的[]PathNode的 Path 部分,直接返回构造出来多个 Node,得到完整的[]PathNode,可继续用于MarshalMany
设计思路:
查找过程是根据传入的 []Path 来循环遍历查找每一层 Path 嵌套里面对应的位置,根据嵌套的 Path 类型(fieldId,mapKey,listIndex),调用对应的 search 函数。不同于源码翻译思路,由于 Node 的自反射性设计,我们可以直接实现字节流定位,无需依赖 Descriptor 查找,并跳过不必要的字段翻译。构造最终返回的 Node 时,根据具体类型看是否需要去除 tag 即可,返回的 []address 刚好在 search 过程中完成了每一层 Path 的 tag 偏移量记录。
动态插入/删除
新增数据思想采用尾插法,保证 pack/unpack 数据的统一性,完成插入操作后需要更新嵌套层 bytelen。
- SetByPath:只支持 root 节点调用,保证 UpdateByLen 更新的完整和正确性。
- SetMany:可支持局部节点插入。
- UnsetByPath:只支持 root 节点调用,思想同插入字段,即找到对应的片段后直接将片段置空,然后更新updatebytelen。
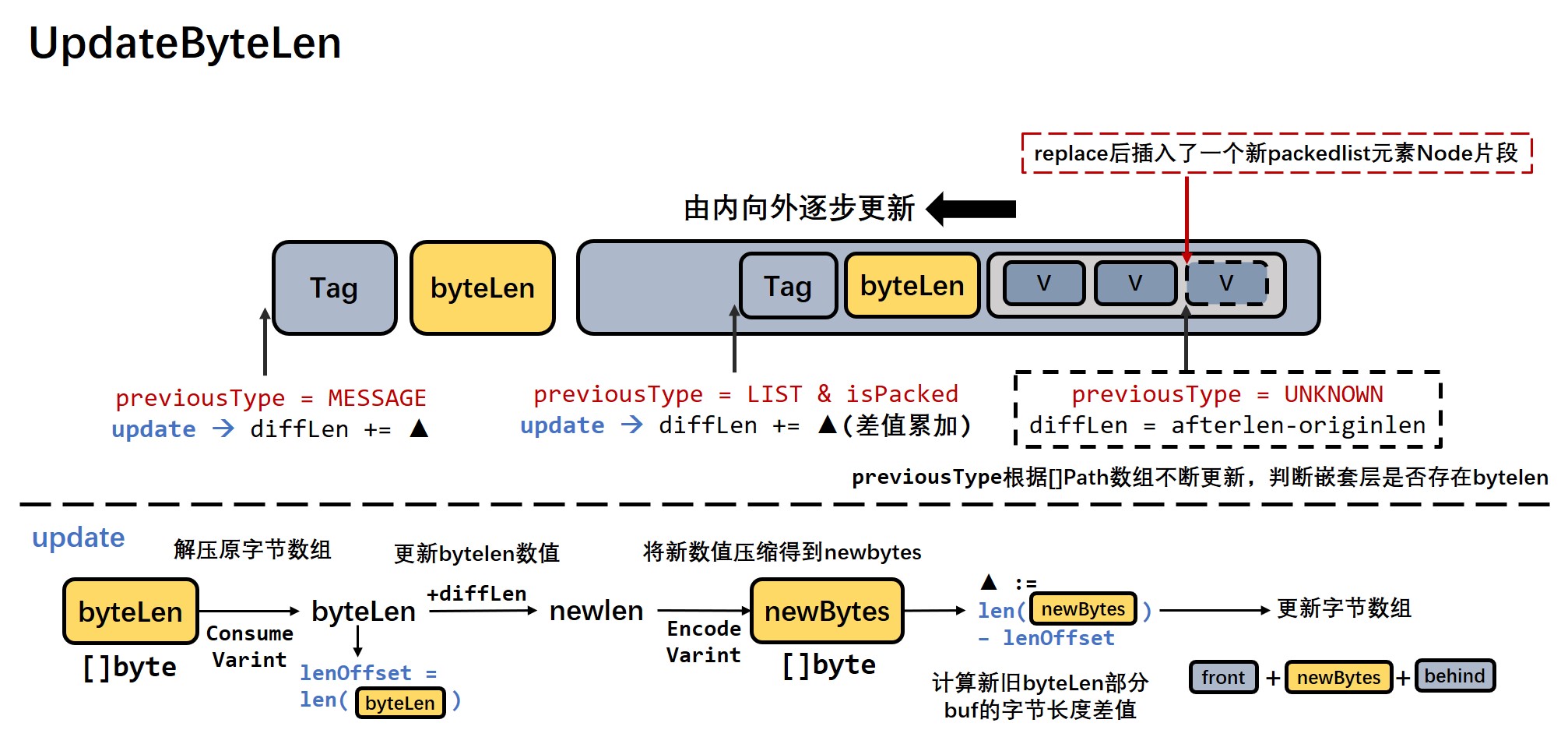
Updatebytelen细节:
- 计算插入完成后新的长度与原长度的差值,存下当前片段增加或者减少的diffLen。
- 从里向外逐步更新
[]Path数组中存在 bytelen 的嵌套层(只有packed list和message)的 bytelen 字节数组。 - 更新规则:先 readTag,然后再 readLength,得到解 varint 压缩后的具体 bytelen 数值,计算 newlen = bytelen + diffLen,计算 newbytelen 压缩后的字节长度与原 bytelen 长度的差值 sublen,并累计diffLen += sublen。
- 指针向前移动到下一个 path 和 address。
DOM序列化
- Marshal:建好 PathNode 后,可遍历拼接 DOM 的所有叶子节点片段,Tag 部分会通过 Path 类型和 Node 类型进行补全,bytelen 根据实际遍历节点进行更新。
- MarshalTo:针对数据裁剪场景,该设计方案具有很好的扩展性,可直接比对新旧 descriptor 中共有的字段 id,对字节流一次性拼接写入,无需依赖中间结构体,可支持多层嵌套字段缺失以及 LIST/MAP 内部元素字段缺失。
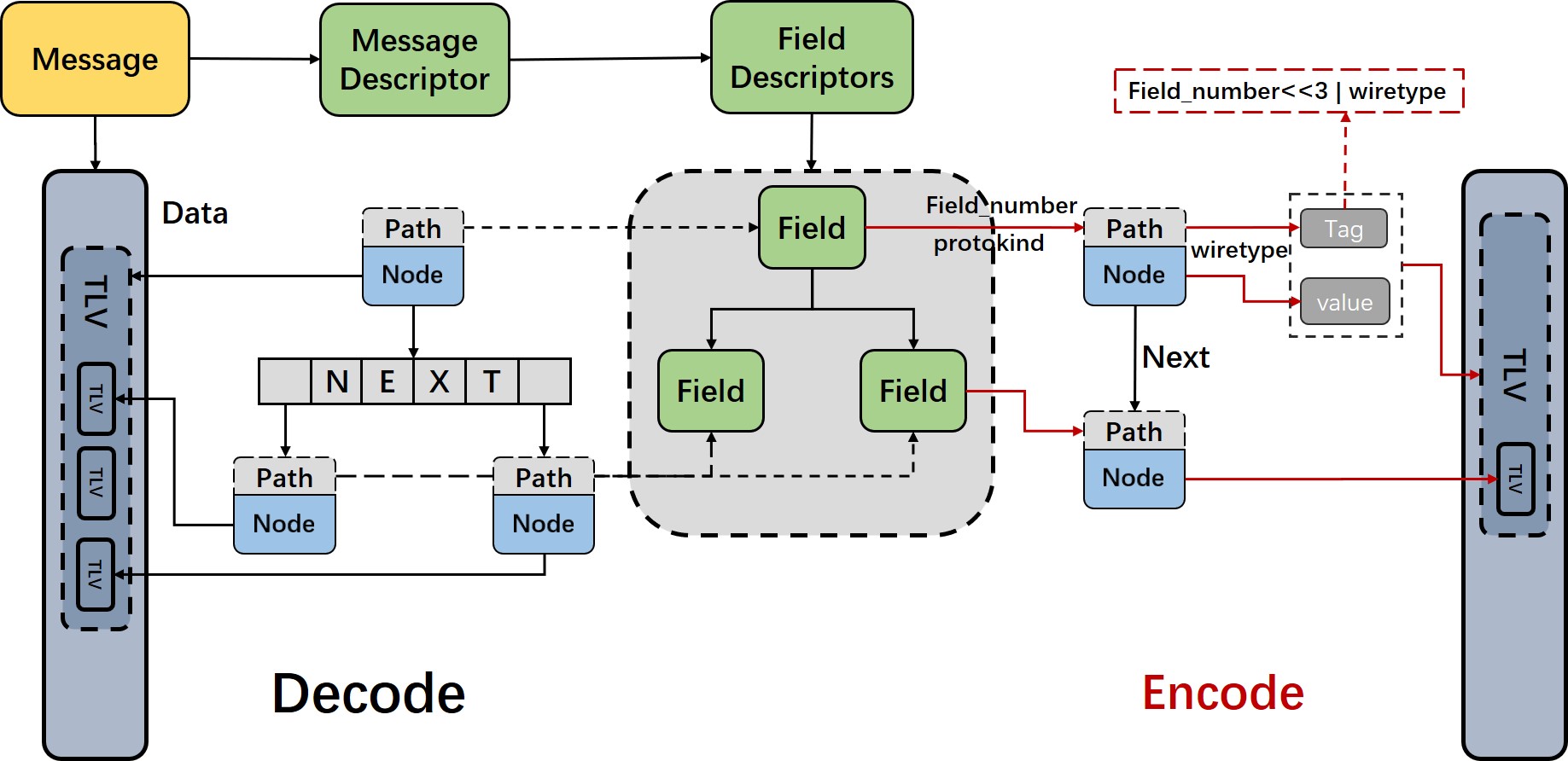
协议转换
ProtoBuf——>JSON
Protobuf->JSON 协议转换的过程可以理解为逐字节解析 ProtoBuf,并结合 Descriptor 类型编码为 JSON 到输出字节流,整个过程是 in-place 进行的,并且结合内存池技术,仅需为输出字节流分配一次内存即可。
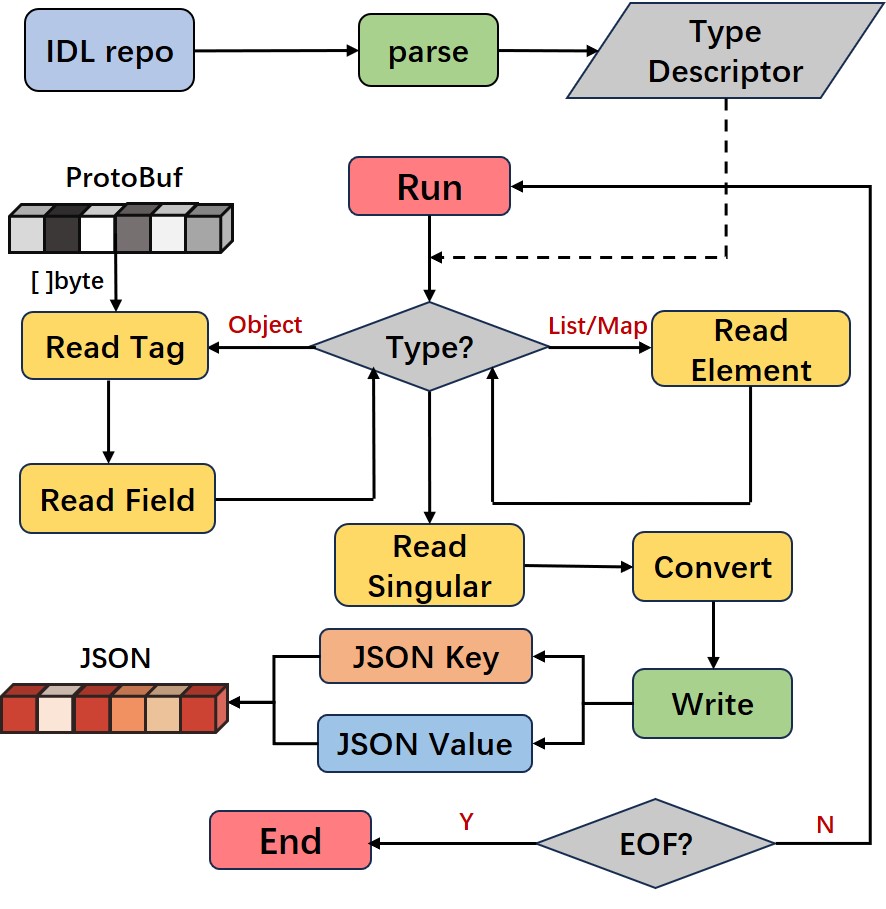
ProtoBuf——>JSON 的转换过程如下:
- 根据输入的 Descriptor 指针类型区分,若为 Singular(string/number/bool/Enum) 类型,跳转到第5步开始编码;
- 按照 Message([Tag] [Length] [TLV][TLV][TLV]….)编码格式对输入字节流执行 varint解码,将Tag解析为 fieldId(字段ID)、wireType(字段wiretype类型);
- 根据第2步解析的 fieldId 确定字段 FieldDescriptor,并编码字段名 key 作为 jsonKey 到输出字节流;
- 根据 FieldDescriptor 确定字段类型(Singular/Message/List/Map),选择不同编码方法编码 jsonValue 到输出字节流;
- 如果是 Singular 类型,直接编码到输出字节流;
- 其它类型递归处理内部元素,确定子元素 Singular 类型进行编码,写入输出字节流中;
- 及时输入字节流读取位置和输出字节流写入位置,跳回2循环处理,直到读完输入字节流。
JSON——>ProtoBuf
协议转换过程中借助 JSON 状态机原理和 sonic 思想,设计 UserNodeStack 实现了接口 Onxxx(OnBool、OnString、OnInt64….)方法达到编码 ProtoBuf 的目标,实现 in-place 遍历 JSON 转换。
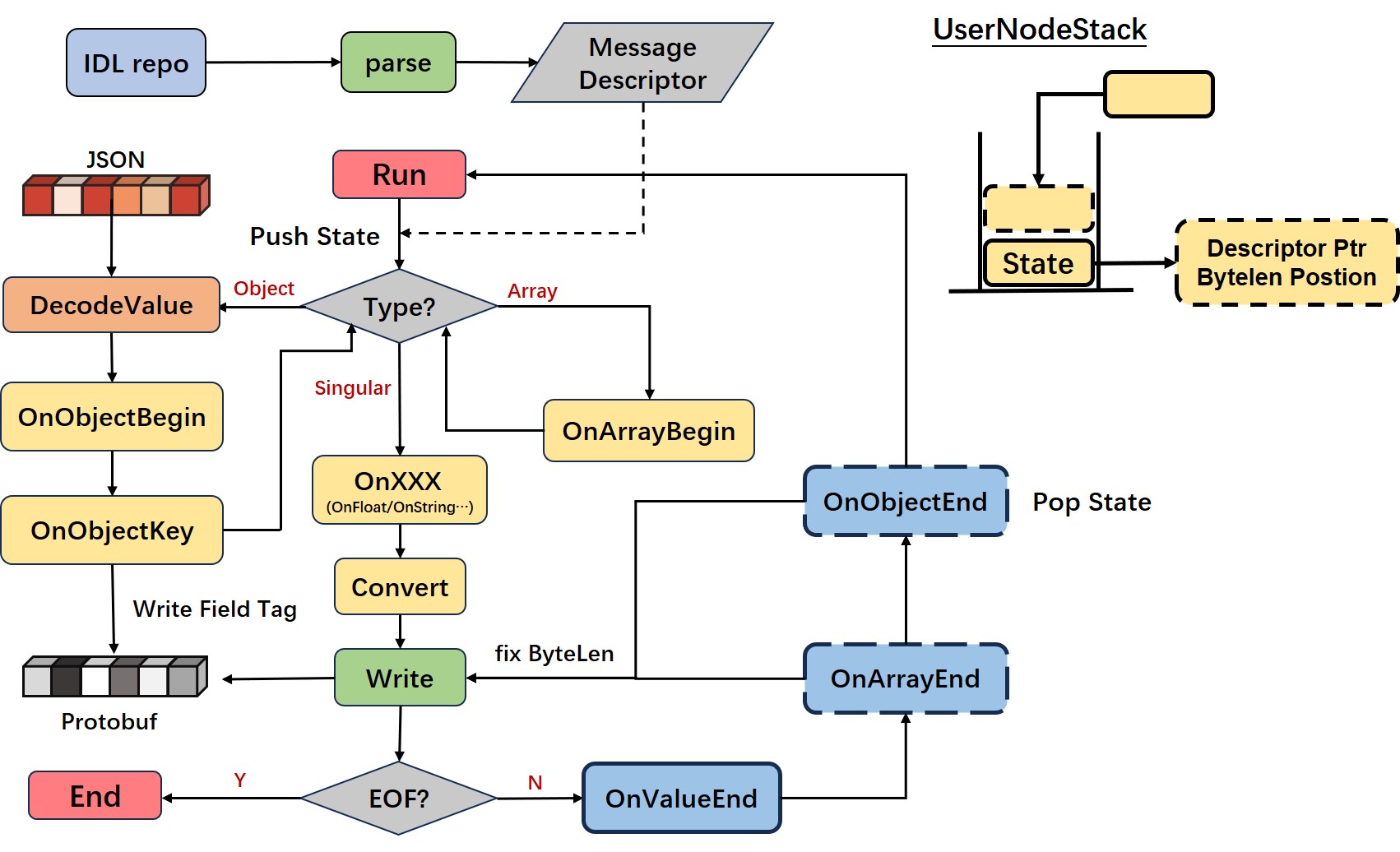
VisitorUserNode 结构
因为在编码 Protobuf 格式的 Mesage/UnpackedList/Map 类型时需要对字段总长度回写,并且在解析复杂类型(Message/Map/List)的子元素时需要依赖复杂类型 Descriptor 来获取子元素 Descriptor,所以需要 VisitorUserNode 结构来保存解析 json 时的中间数据。
|
- stk:记录解析时中间变量的栈结构,在解析 Message 类型时记录 MessageDescriptor、PrefixLen;在解析 Map 类型时记录 FieldDescriptor、PairPrefixLen;在解析 List 类型时记录 FieldDescriptor、PrefixListLen;
- sp:当前所处栈的层级;
- p:输出字节流;
- globalFieldDesc:每当解析完 MessageField 的 jsonKey 值,保存该字段 Descriptor 值;
VisitorUserNodeStack 结构
记录解析时字段 Descriptor、回写长度的起始地址 PrefixLenPos 的栈结构。
|
- typ:当前字段的类型,取值有对象类型(objStkType)、数组类型(arrStkType)、哈希类型(mapStkType);
- state:存储详细的数据值;
visitorUserNodeState 结构
|
- msgDesc:记录 root 层的动态类型描述 MessageDescriptor;
- fieldDesc:记录父级元素(Message/Map/List)的动态类型描述 FieldDescriptor;
- lenPos:记录需要回写 PrefixLen 的位置;
协议转换过程
JSON——>ProtoBuf 的转换过程如下:
- 从输入字节流中读取一个 json 值,并判断其具体类型(
object/array/string/float/int/bool/null); - 如果是 object 类型,可能对应 ProtoBuf MapType/MessageType,sonic 会按照
OnObjectBegin()->OnObjectKey()->decodeValue()...顺序处理输入字节流
OnObjectBegin()阶段解析具体的动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 jsonKey 并以 ProtoBuf 格式编码 Tag、Length 到输出字节流;decodeValue()阶段递归解析子元素并以 ProtoBuf 格式编码 Value 部分到输出字节流,若子类型为复杂类型(Message/Map),会递归执行第 2 步;若子类型为复杂类型(List),会递归执行第 3 步。
- 如果是 array 类型,对应 ProtoBuf PackedList/UnpackedList,sonic 会按照
OnObjectBegin()->OnObjectKey()->OnArrayBegin()->decodeValue()->OnArrayEnd()...顺序处理输入字节流
OnObjectBegin()阶段处理解析 List 字段对应动态类型描述 FieldDescriptor 并压栈;OnObjectKey()阶段解析 List 下子元素的动态类型描述 FieldDescriptor 并压栈;OnArrayBegin()阶段将 PackedList 类型的 Tag、Length 编码到输出字节流;decodeValue()阶段循环处理子元素,按照子元素类型编码到输出流,若子元素为复杂类型(Message),会跳转到第 2 步递归执行。
- 在结束处理某字段数据后执行
onValueEnd()、OnArrayEnd()、OnObjectEnd(),获取栈顶lenPos数据,对字段长度部分回写并退栈。 - 更新输入和输出字节流位置,跳回第 1 步循环处理,直到处理完输入流数据。
性能测试
构造与 Thrift 性能测试基本相同的baseline.proto 文件,定义了对应的简单( Small )、复杂( Medium )、简单缺失( SmallPartial )、复杂缺失( MediumPartial ) 两个对应子集,并用 kitex 命令生成了对应的 baseline.pb.go 。 主要与 Protobuf-Go 官方源码进行比较,部分测试与 kitex-fast 也进行了比较,测试环境如下:
- OS:Windows 11 Pro Version 23H2
- GOARCH: amd64
- CPU: 11th Gen Intel(R) Core(TM) i5-1135G7 @ 2.40GHz
- Go VERSION:1.20.5
反射
- 图中列举了 DOM 常用操作的性能,测试细节与 thrift 相同。
- MarshalTo 方法:相比 ProtobufGo 提升随着数据规模的增大趋势越明显,ns/op 开销约为源码方法的0.29 ~ 0.32。
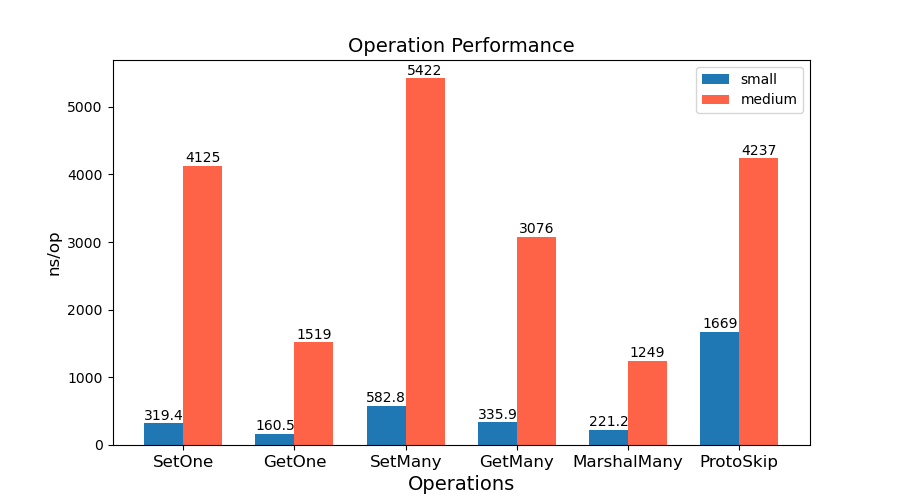
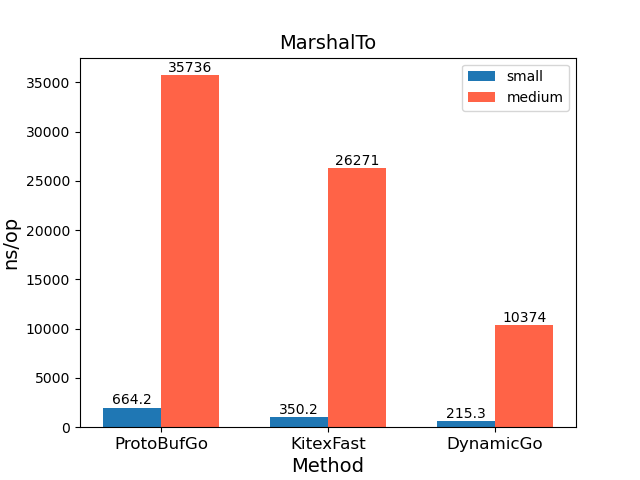
字段Get/Set定量测试
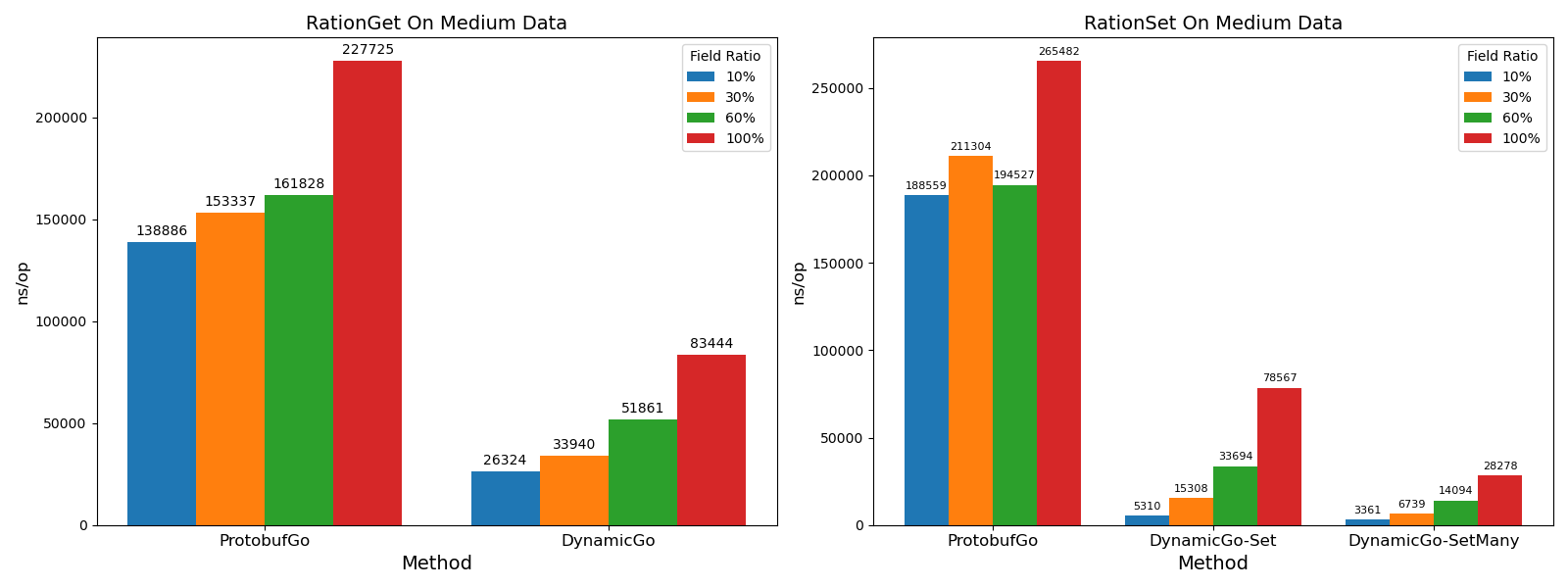
- factor 用于修改从上到下扫描 proto 文件字段获取比率。
- 定量测试比较方法是 ProtobufGo 的 dynamicpb 模块和 DynamicGo 的 Get/SetByPath,SetMany,测试对象是medium data 的情况。
- Set/Get 字段定量测试结果均优于 ProtobufGo,且在获取字段越稀疏的情况下性能加速越明显。
- Setmany 性能加速更明显,在 100% 字段下 ns/op 开销约为 0.11。
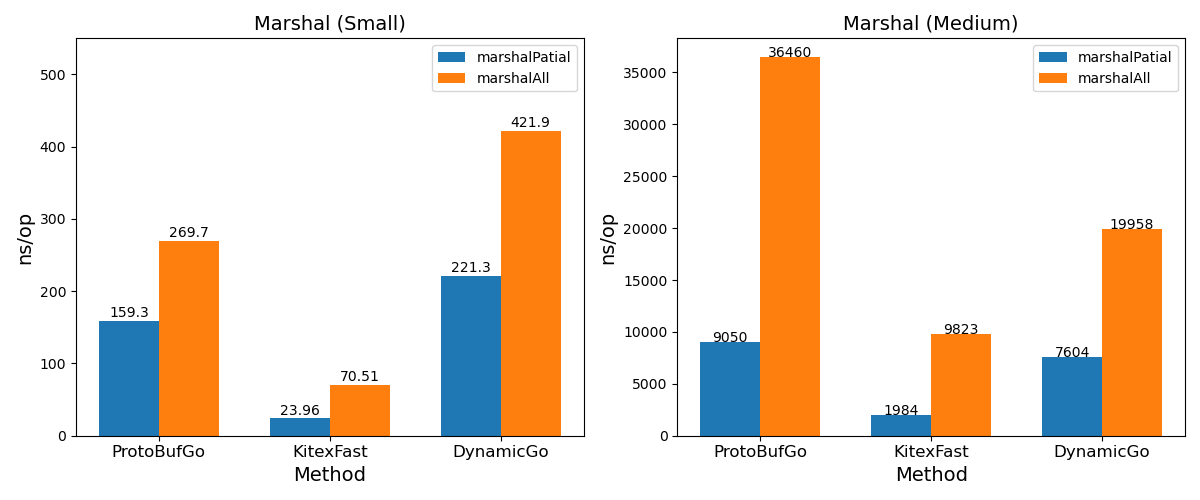
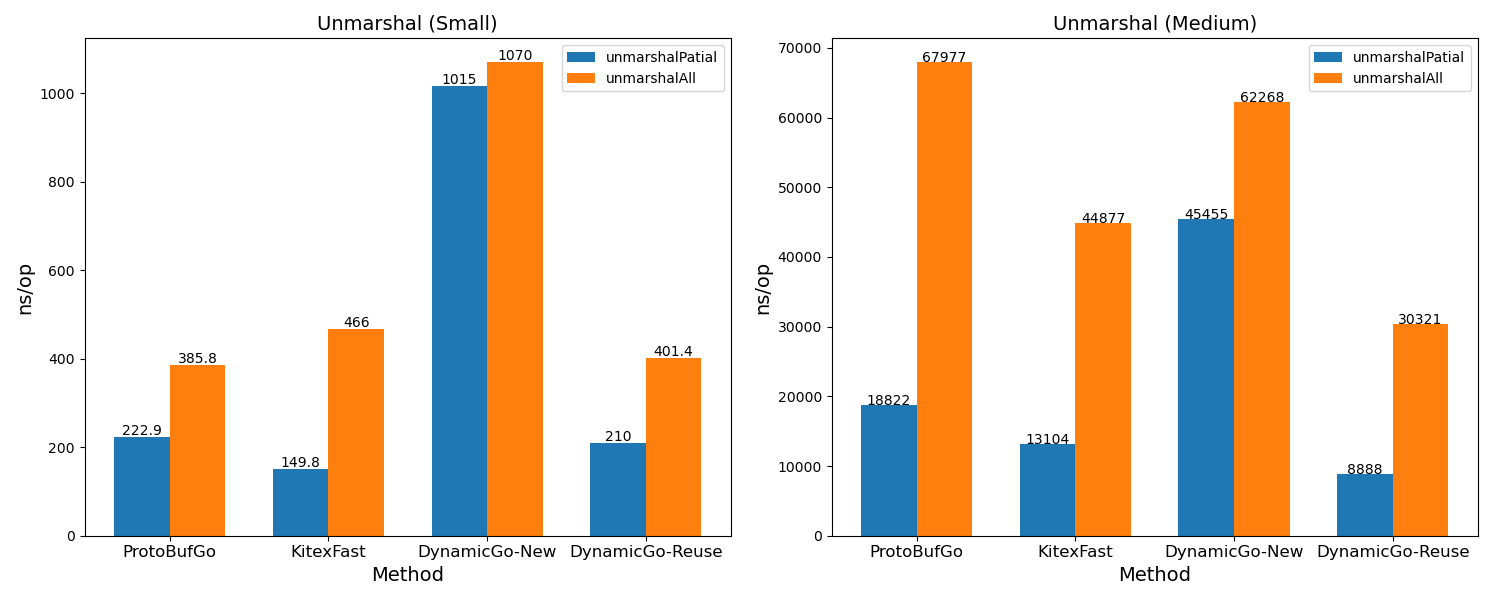
序列化/反序列
- 序列化在 small 规模略高于 ProtobufGo,medium 规模的数据上性能优势更明显,ns/op 开销约为源码的0.54 ~ 0.84。
- 反序列化在 reuse 模式下,small 规模略高于 ProtobufGo,在 medium 规模数据上性能优势更明显,ns/op 开销约为源码的0.44 ~ 0.47,随数据规模增大性能优势增加。
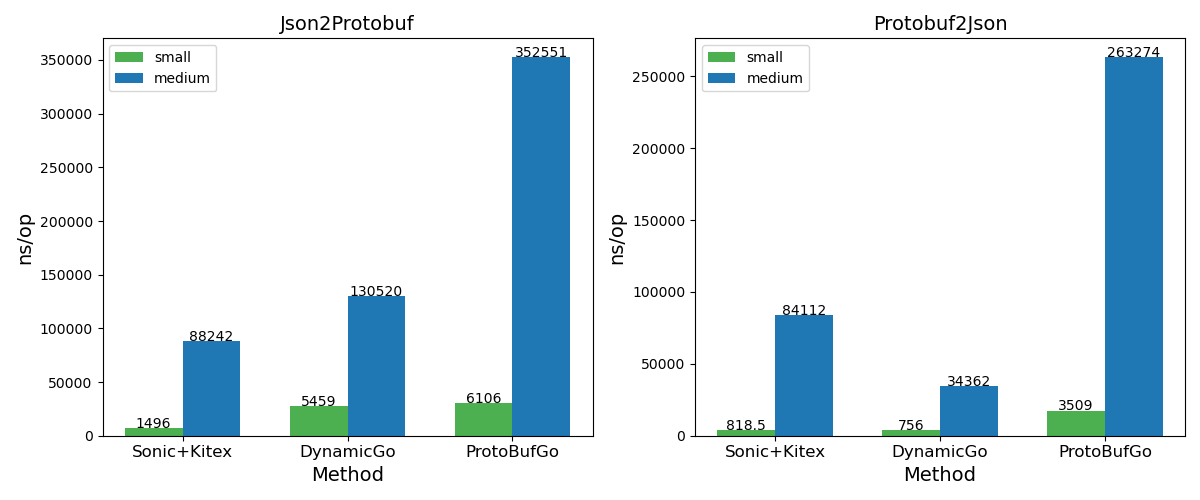
协议转换
- Json2Protobuf 优于 ProtobufGo,ns/op 性能开销约为源码的0.21 ~ 0.89,随着数据量规模增大优势增加。
- Protobuf2Json 性能明显优于 ProtobufGo,ns/op 开销约为源码的0.13 ~ 0.21,而相比 Kitex,ns/op 约为Sonic+Kitex 的0.40 ~ 0.92,随着数据量规模增大优势增加。
应用与展望
目前 dynamicgo 对于 Protobuf 协议的可支持的功能包括:
- 替代官方源码的 JSON 协议转换,实现更高性能的 HTTP<>PB 动态网关
- 支持 IDL 内存字符串动态解析和数据泛化调用,可辅助 Kitex 提升 Protobuf 泛化调用模块性能。
- 支持动态数据裁剪、聚合等 DSL 场景,实现高性能 PB BFF 网关。
目前 dynamicgo 还在迭代中,接下来的工作包括:
- 支持 Protobuf 特殊字段,如 Enum,Oneof 等;
- 对于 Protobuf 协议转换提供 Http-Mapping 的扩展和支持;
- 继续扩展优化多种协议之间的泛化调用过程,集成到 Kitex 泛化调用模块中;
也欢迎感兴趣的个人或团队参与进来,共同开发!
代码仓库:https://github.com/cloudwego/dynamicgo
本文作者:尹可汗,徐健猇、段仪 | 来自:官方微信推文